
Spotify Scrape: John Mayer Edition
I scraped the discography of my favorite artist -- let me show you how I did it!
John Mayer has got to be one of my favorite artists of all time – I’ve seen him in concert 6 times, gone to concerts in 3 different states, and I’ve got a joint playlist with my mom that shares our top favorite songs.
Are there certain aspects of John Mayer’s artistry that make me so prone to enjoying his music? In today’s digital world of music, there are a lot of specially-calculated metrics that define a song – can I come up with a statistically-backed explanation as to why I like his music the most? Do all of his songs follow similar patterns and trends in terms of style, key signature, length, etc.?
In order to get a closer look at his music (and to find data for my project that was interesting to me and not too trivial), I decided to try and scrape John Mayer’s discography off of Spotify!
Hold on, you can legally scrape data from Spotify??
Spotify is one of the largest, if not the largest, music streaming service providers in the world. Surely a billion-dollar company such as Spotify has numerous hoops that one has to jump through in order to legally access its data, right?
Short answer: yes. However, Spotify does have some established developer tools that help make this process less tedious and clearly define the policies and ethics of accessing their data.
Thankfully, Spotify has a free Web API that anyone can access when they agree to their Terms of Service. Creating an account on the Spotify Developers website provides you with a unique client id and client secret that authorizes your ability to scrape their data. Not too bad!

I won’t go super into detail on this process, but if you want to try it on your own, Spotify has a quick start guide that provides more instruction.
NOTE: One significant aspect of the Spotify Web API is that it only allows scrapes of up to 100 tracks per session. While there may be ways to work around this in a convoluted way, for purposes of this assignment I had permission from Dr. Tass to just focus on the scrape from a singular session. John Mayer has several studio and live albums, which makes his total track list exceed 100 songs. To account for this, I created a playlist of just his studio albums, and used the last couple of indeces to add a few of my favorite live recordings. So while it’s not John Mayer’s entire discography, it’s pretty close.
I got the API, now what?
Once I had my credentials, I just needed to get the URI for the playlist I wanted to scrape! On the mac desktop app, this can be obtained by pressing the three dots at the top of the playlist, going to “share”, and selecting “Copy playlist URI” while holding down the ‘option’ key.
Once I got the URI, Python (thankfully) has a relatively lightweight package called Spotipy that helps decipher the music data accessible from the Spotify Web API. For organizational and security purposes, I saved my client keys and URI in separate json files and called those rather than typing them directly. If you decide to take this route (which is recommended if you will be publishing code in a repository, etc.), you’ll want to import the json package as well.
import spotipy
from spotipy.oauth2 import SpotifyClientCredentials
import json
# access my json file and assign my private client credentials
credentials = json.load(open('authorization.json'))
client_id = credentials['client_id']
client_secret = credentials['client_secret']
# access my json file with the playlist uri from my John Mayer playlist
playlist_index = 0
playlists = json.load(open('playlists.json'))
playlist_uri = playlists[playlist_index]['uri']
From here, I assigned my client credentials via spotipy with these two lines of code:
client_credentials_manager = SpotifyClientCredentials(client_id=client_id,client_secret=client_secret)
sp = spotipy.Spotify(client_credentials_manager=client_credentials_manager)
The actual scraping part
Once I was certified, it was time to grab the actual data – aka the fun stuff.
Before I scraped anything, I needed to understand what exactly I would be scraping. That sounds dumb, but it really was just that. I realized that I would ultimately need to scrape two “tables” of data: one table with the track id’s, titles, and artist(s), and one table with the feature information relevant to those tracks.
To access the basic track information, I directly accessed my URI and stored the username and id for use in the spotipy function called user_playlist(). From here, I created empty sets that would populate the track and artist information. The artist information is a bit redundant in this case since my playlist is just John Mayer, but if I wanted to change the URI in my json file to a different playlist, this allows my code to still work!
results = sp.user_playlist(username, playlist_id, 'tracks')
# create empty sets for playlist track ids, artists, etc.
playlist_tracks_data = results['tracks']
playlist_tracks_id = []
playlist_tracks_titles = []
playlist_tracks_artists = []
# grab track, name, and artist contained in playlist
for track in playlist_tracks_data['items']:
playlist_tracks_id.append(track['track']['id'])
playlist_tracks_titles.append(track['track']['name'])
# adds a list of all artists involved in the song to the list of artists for the playlist
# (I don't really need this for this playlist since it's all John Mayer, but its good for reproducibility)
artist_list = []
for artist in track['track']['artists']:
artist_list.append(artist['name'])
playlist_tracks_artists.append(artist_list)
To access more in-depth information, I found another link on Spotify’s Developer Website that defines a variety of audio features that are accessible through spotipy. Below are some notable features listed on their site:
- Danceability: describes how suitable a track is for dancing based on a combination of musical elements including tempo, rhythm stability, beat strength, and overall regularity. A value of 0.0 is least danceable and 1.0 is most danceable.
- duration_ms: the duration of a track in miliseconds
- Tempo: The overall estimated tempo of a track in beats per minute (BPM). In musical terminology, tempo is the speed or pace of a given piece and derives directly from the average beat duration.
- Valence: A measure from 0.0 to 1.0 describing the musical positiveness conveyed by a track. Tracks with high valence sound more positive (e.g. happy, cheerful, euphoric), while tracks with low valence sound more negative (e.g. sad, depressed, angry).
Luckily, these can all be accessed using just one line of code!
# grab audio features for playlist
features = sp.audio_features(playlist_tracks_id)
From here, I created a pandas dataframe that combined the audio features and playlists tracks into one dataset!

Final Touches
For this project, I decided to only include features that I thought were the most interesting and interpretable. After removing these (along with the redundant ‘artist’ column) and converting some columns to be more interpretable (I will figure out how to convert ‘duration’ from integer to mm:ss format another day, lol), this is what my dataset ended up looking like!
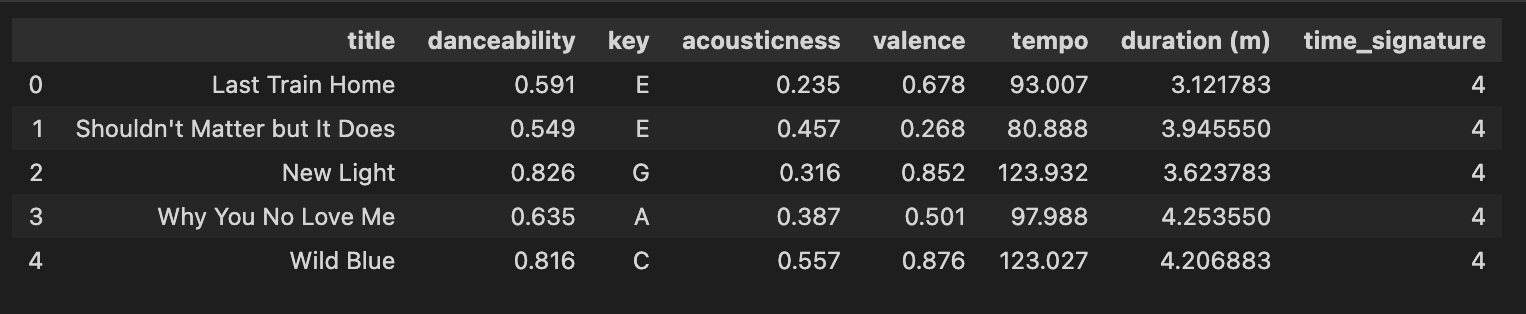
Conclusion
This blog was mostly just to demonstrate how I (legally and ethically) obtained an API to source data of interest to me! In my next blog post, I will dive deeper into this data and actually use it to answer questions! Are you curious to know the “danceability” of the average John Mayer song? Or perhaps you’re curious to know how positive or negative his lyrics are, on average? If so, check out my Exploratory Data Analysis, coming soon!
If you want to see the code that I utilized for this project in more detail, here is the link to my github repository where I have my .json files (except for the one with my private key) and a commented .ipynb python file!
This link also walks through some other fun things that you can do with the spotipy package, such as pulling album lists and even album covers!
Happy coding!